درس ۰۸: ساختمانهای داده در پایتون: list و tuple¶

Photo by Maria Orlova¶
از درس هفتم با انواع داده پایه در پایتون آشنا شدهایم و در این درس به بررسی انواع داده دیگری خواهیم پرداخت که در زبانهای برنامهنویسی عموما با عنوان ساختمانهای داده بیان میشوند. ساختمانهای داده یا Data Structures به اشیایی گفته میشود که برای نگهداری از یک مجموعه داده طراحی شدهاند و هر یک دارای ویژگی منحصربهفرد خود است. برای مثال قابل تغییر بودن، امکان حفظ ترتیب اعضا، امکان نگهداری دادههای تکراری یا تنها اجبار به نگهداری دادههای یکتا که هر یک مناسب وضعیت خاصی در برنامهنویسی هستند. این درس به بررسی چهار ساختمان داده متداول در پایتون خواهد پرداخت: لیست (list)، توپِل (tuple)، مجموعه (set) و دیکشنری (dict)
به منظور جلوگیری از طولانی شدن متن درس و همینطور سادگی در مطالعه، محتوا این درس در قالب دو بخش ارایه میشود که بخش نخست تنها به شرح لیست (list) و توپِل (tuple) خواهد پرداخت.
✔ سطح: مقدماتی
لیست¶
نوع «لیست» (List) یک نوع بسیار انعطافپذیر در پایتون میباشد. این نوع همانند رشته یک «دنباله» (Sequence) بوده ولی برخلاف آن یک نوع «تغییر پذیر» (Mutable) است. شی لیست با استفاده از کروشه [ ] ایجاد میگردد و ترتیب اعضا را حفظ و میتواند عضوهایی - از هر نوع - داشته باشد که توسط کاما , از یکدیگر جدا میشوند؛ نوع لیست در واقع محلی برای نگهداری اشیا گوناگون و تغییرپذیر است:
>>> L = [1, 2, 3]
>>> type(L)
<class 'list'>
>>> L
[1, 2, 3]
>>> print(L)
[1, 2, 3]
>>> import sys
>>> sys.getsizeof(L)
88
>>> L = [] # An empty list
>>> L
[]
عضوهای لیست میتوانند از هر نوعی باشند؛ حتی یک لیست:
>>> L = [15, 3.14, 'string', [1, 2]]
شی لیست جزو انواع دنباله پایتون است و میتوان عضوها را بر اساس اندیس موقعیت آنها دستیابی نمود:
>>> L = [1, 2, 3]
>>> L[0]
1
>>> L[-1]
3
و همچنین تعداد عضوهای هر شی لیست را توسط تابع ()len [اسناد پایتون] به دست آورد:
>>> L1 = []
>>> len(L1)
0
>>> L2 = ['python', 12.06]
>>> len(L2)
2
>>> len(L2[0])
6
>>> L3 = ['a', [1, 2], 'b']
>>> len(L3)
3
>>> len(L3[1])
2
چنانچه یک دنباله جزو عضوهای شی لیست باشد، با استفاده از الگو [seq[i][j میتوان عضوهای آن را نیز دستیابی نمود که در آن i اندیسی است که به یک عضو شی لیست اشاره دارد و j نیز اشاره به اندیس داخلی عضو i دارد؛ این الگو به همین شیوه میتواند ادامه یابد:
>>> L = ['python', 2.56]
>>> L[0]
'python'
>>> L[0][:2]
'py'
>>> L = ['python', 2.56, [128, ['a', 'z']]]
>>> L[2][1][0]
'a'
یکی از مثالهای رایج شی لیست، شبیهسازی ساختار ماتریس (Matrix) است:
>>> L = [[1, 2, 3],
... [4, 5, 6],
... [7, 8, 9]]
>>>
>>> L
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> L[0][1]
2
شی لیست جزو انواع Mutable پایتون است و میتوان عضوهای آن را تغییر داد؛ این تغییر میتواند به شکل حذف، درج عضو جدید یا جایگزین کردن یک یا چند عضو باشد. پایتون متدهای کاربردی زیادی برای دستکاری و تغییر شی لیست دارد که در ادامه به آنها نیز خواهیم پرداخت ولی در این بخش میخواهیم به بررسی چگونگی ایجاد تغییر با استفاده از عملگر انتساب بپردازیم:
جایگزین کردن:
>>> L = [1, 2, 3] >>> L[1] = 'py' >>> L [1, 'py', 3]
>>> L = [1, 2, 3, 4, 5, 6] >>> L[:2] = [0, 0] >>> L [0, 0, 3, 4, 5, 6]
درج کردن -
iدر الگو[seq[i:iبه موقعیتی از شیseqاشاره دارد که میخواهیم درج در آن نقطه انجام شود؛ در این شیوه توجه داشته باشید که شیای که میخواهید درون لیست درج کنید میبایست یک دنباله باشد:>>> L = [0, 1, 5, 6] >>> L[2:2] = [2, 3, 4] >>> L [0, 1, 2, 3, 4, 5, 6] >>> L[0:0] = 'abc' >>> L ['a', 'b', 'c', 0, 1, 2, 3, 4, 5, 6] >>> L[3:3] = ['d', [-2, -1]] >>> L ['a', 'b', 'c', 'd', [-2, -1], 0, 1, 2, 3, 4, 5, 6]
حذف کردن - کافی است یک شی لیست خالی (
[]) را به یک یا چند عضو از شی لیست مورد نظر انتساب دهیم:>>> L = [0, 1, 2, 3, 4, 5, 6] >>> L[2:5] = [] >>> L [0, 1, 5, 6]
دستور del¶
با استفاده از دستور del [اسناد پایتون] نیز میتوان یک عضو یا یک تکه از شی لیست را حذف کرد:
>>> L = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> del L[2]
>>> L
['a', 'b', 'd', 'e', 'f', 'g']
>>> del L[1:4]
>>> L
['a', 'f', 'g']
همچنین میتوانیم از این دستور برای حذف کامل یک متغیر استفاده نماییم. با حدف یک متغیر، ارجاع آن به شی نیز حذف میشود و چنانچه هیچ ارجاع دیگری به آن شی وجود نداشته باشد، شیای که متغیر به آن ارجاع داشت نیز از حافظه حذف میگردد:
>>> a = 5
>>> a
5
>>> del a
>>> a
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'a' is not defined
انتساب چندگانه¶
میتوان یک شی لیست - یا در کل یک شی دنباله - را به تعدادی نام انتساب داد و متغیرهای جداگانهای ایجاد نمود؛ این عمل Unpacking خوانده میشود. در این شرایط مفسر پایتون هر عضو دنباله را با حفظ ترتیب به یکی از نامها انتساب میدهد که در حالت عادی میبایست تعداد نامها با عضوهای دنباله برابر باشد:
>>> L = [1.1, 2.2, 3.3, 4.4]
>>> a, b, c, d = L
>>> a
1.1
>>> b
2.2
>>> c
3.3
>>> d
4.4
>>> a, b = [1.1, 2.2, 3.3, 4.4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)
ولی میتوان یکی از نامها را توسط نماد * نشانهگذاری کرد؛ در این شرایط مفسر پایتون توازنی را بین عضوهای دنباله و نامها ایجاد میکند که در این حالت تمام عضوهای اضافی - در قالب یک شی لیست - به نام نشانهگذاری شده انتساب داده میشود. البته باید توجه داشت که ترتیب عضوهای دنباله در هر شرایطی رعایت خواهد شد؛ به نمونه کدهای پایین توجه نمایید:
>>> L = [1.1, 2.2, 3.3, 4.4]
>>> a, b, *c = L
>>> a
1.1
>>> b
2.2
>>> c
[3.3, 4.4]
>>> *a, b = [1.1, 2.2, 3.3, 4.4]
>>> a
[1.1, 2.2, 3.3]
>>> b
4.4
>>> a, *b, c = [1.1, 2.2, 3.3, 4.4]
>>> a
1.1
>>> b
[2.2, 3.3]
>>> c
4.4
>>> a, b, c, *d = [1.1, 2.2, 3.3, 4.4]
>>> a
1.1
>>> b
2.2
>>> c
3.3
>>> d
[4.4]
کپی کردن¶
همانند دیگر اشیا میتوان با انتساب یک متغیر موجود از شی لیست به یک نام جدید، متغیر دیگری از این نوع شی ایجاد کرد. البته همانطور که پیشتر نیز بیان شده است؛ در این حالت شی کپی نمیگردد و تنها یک ارجاع جدید از این نام جدید به شی آن متغیر داده میشود. این موضوع با استفاده از تابع ()id [اسناد پایتون] قابل آزمودن است؛ خروجی این تابع برابر نشانی شی در حافظه میباشد و بدیهی است که دو مقدار id یکسان برای دو متغیر نشان از یکی بودن شی آنهاست:
>>> L1 = [1, 2, 3]
>>> L2 = L1
>>> L2
[1, 2, 3]
>>> id(L1)
140254551721800
>>> id(L2)
140254551721800
عضوهای یک شی لیست تغییر پذیر هستند و باید توجه داشته باشیم اکنون که هر دو متغیر به یک شی اشاره دارند اگر توسط یکی از متغیرها، عضوهای شی مورد نظر تغییر داده شوند، مقدار مورد انتظار ما از شی متغیر دوم نیز تغییر خواهد کرد:
>>> L1 = [1, 2, 3]
>>> L2 = L1
>>> L1[0] = 7
>>> L1
[7, 2, 3]
>>> L2
[7, 2, 3]
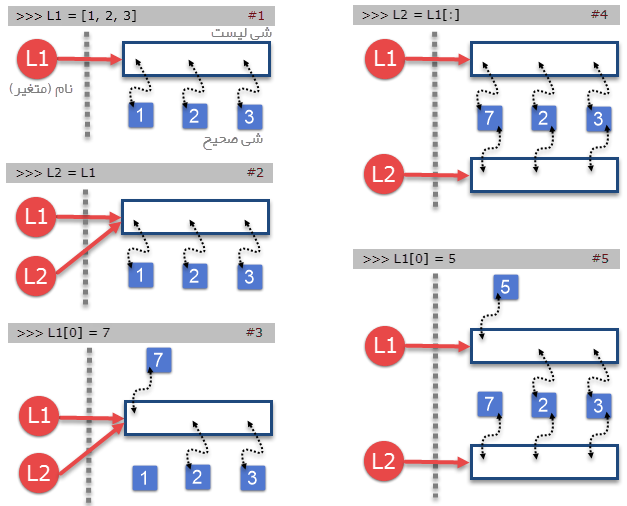
اگر این موضوع را یک مشکل بدانیم برای رفع آن میتوان از شی متغیر یک کپی ایجاد کرده و این کپی را به متغیر جدید نسبت دهیم؛ در این شرایط هر دو متغیر به اشیایی جداگانه در محلهایی متفاوت از حافظه اشاره خواهند داشت. در حالت عادی برای کپی کردن یک شی لیست نیاز به کار جدیدی نیست و میتوان از اندیس گذاری [:] - به معنی تمامی عضوها - استفاده کرد:
>>> L1
[7, 2, 3]
>>> L2 = L1[:]
>>> L1
[7, 2, 3]
>>> L2
[7, 2, 3]
>>> id(L1)
140254551721928
>>> id(L2)
140254551721800
>>> L1[0] = 5
>>> L1
[5, 2, 3]
>>> L2
[7, 2, 3]
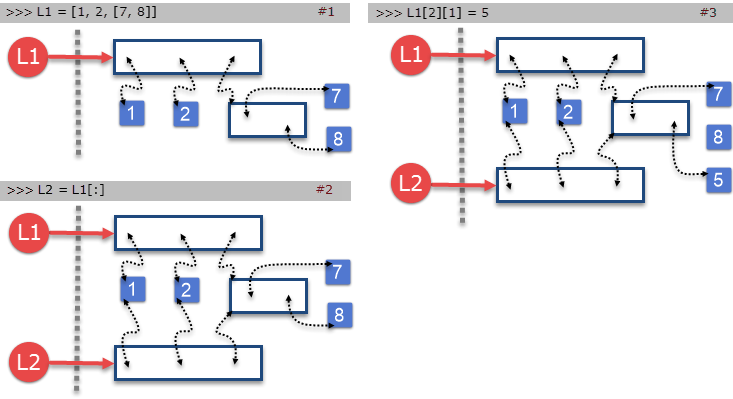
ولی اگر شی لیست مورد نظر عضوهایی از نوع لیست (یا هر نوع تغییر پذیر دیگر) داشته باشد، مشکل فوق همچنان برای این عضوها باقی است. به نمونه کد و تصویر پایین توجه نمایید:
>>> L1 = [1, 2, [7, 8]]
>>> L2 = L1[:]
>>> L2
[1, 2, [7, 8]]
>>> L1[2][1] = 5
>>> L1
[1, 2, [7, 5]]
>>> L2
[1, 2, [7, 5]]
>>> id(L1)
140402644179400
>>> id(L2)
140402651379720
>>> id(L1[2])
140402644179080
>>> id(L2[2])
140402644179080
در پایتون کپی شی به دو شیوه «سطحی» (Shallow Copy) و «عمیق» (Deep Copy) انجام میشود که به ترتیب توسط تابعهای ()copy و ()deepcopy از درون ماژول copy در دسترس هستند [اسناد پایتون]. در شیوه کپی سطحی همانند کاری که پیش از این انجام دادیدم - یعنی انتساب با استفاده از اندیس [:] - اشیا داخلی کپی نمیشوند و تنها یک ارجاع جدید به آنها داده میشود؛ در حالی که توسط شیوه کپی عمیق از تمامی اشیا (تغییر پذیر) داخلی نیز یک کپی ایجاد میگردد:
>>> L1 = [1, 2, [7, 8]]
>>> import copy
>>> L2 = copy.copy(L1) # Shallow Copy
>>> L1[2][1] = 5
>>> L1
[1, 2, [7, 5]]
>>> L2
[1, 2, [7, 5]]
>>> L1 = [1, 2, [7, 8]]
>>> import copy
>>> L2 = copy.deepcopy(L1) # Deep Copy
>>> L1[2][1] = 5
>>> L1
[1, 2, [7, 5]]
>>> L2
[1, 2, [7, 8]]
>>> id(L1)
140402651379656
>>> id(L2)
140402644179400
>>> id(L1[2])
140402644106312
>>> id(L2[2])
140402651379080
عملگرها برای لیست¶
میتوان از عملگرهای + (برای پیوند لیستها) و * (برای تکرار عضوهای لیست) بهره برد:
>>> [1, 2] + [2, 3] + [3, 4]
[1, 2, 2, 3, 3, 4]
>>> ['python'] * 3
['python', 'python', 'python']
برای بررسی برابر بودن مقدار دو شی لیست مانند دیگر اشیا میتوان از عملگر == استفاده کرد:
>>> [1, 'python'] == [1, 'python']
True
>>> [1, 'python'] == [1, 'PYTHON']
False
از عملگرهای عضویت هم میتوان برای بررسی وجود شیای درون لیست استفاده کرد:
>>> L = ['a', [1, 2]]
>>> 'b' not in L
True
>>> 2 in L
False
>>> [1, 2] in L
True
تفاوت عملگرهای == و is¶
نکتهای که در درسهای پیش مطرح نشد، بیان تفاوت بین عملگر برابری و عملگر هویت است. پیش از ارایه توضیح به نمونه کد پایین توجه نمایید:
>>> a = 5
>>> b = a
>>> a == b
True
>>> a is b
True
>>> L1 = [1, 2, 3]
>>> L2 = L1
>>> L1 == L2
True
>>> L1 is L2
True
>>> L2 = L1[:]
>>> L1 == L2
True
>>> L1 is L2 # False!
False
از درس پنجم به یاد داریم که هر شی در پایتون حاوی یک «شناسه» (identity)، یک «نوع» (type) و یک «مقدار» (value) است. عملگر == دو شی را از نظر یکسان بودن «مقدار» مورد بررسی قرار میدهد در حالی که عملگر is دو شی را از نظر یکسان بودن «شناسه» (خروجی تابع ()id) یا همان نشانی آنها در حافظه مورد بررسی قرار میدهد.
پیش از این هم بیان شده بود که مفسر پایتون برای صرفهجویی در زمان و حافظه از ساخت مجدد اشیا نوع «صحیح» و «رشته» کوچک موجود اجتناب میکند و تنها یک ارجاع جدید به آنها میدهد. اما این موضوع در مورد اشیا دیگر درست نمیباشد و مفسر پایتون برای هر متغیری که برای این نوع اشیا تعریف میگردد یک شی جدید ایجاد میکند و به آن ارجاع میدهد:
>>> a = 5
>>> b = 5
>>> a == b
True
>>> a is b
True
>>> m = 'python'
>>> n = 'python'
>>> m == n
True
>>> m is n
True
>>> L1 = [1, 2, 3]
>>> L2 = [1, 2, 3]
>>> L1 == L2
True
>>> L1 is L2 # False!
False
تبدیل به شی لیست¶
با استفاده از کلاس ()list [اسناد پایتون] میتوان یک شی لیست ایجاد کرد یا اشیایی که از نوع دنباله هستند را به یک شی لیست تبدیل نمود:
>>> a = 'python'
>>> type(a)
<class 'str'>
>>> b = list(a)
>>> type(b)
<class 'list'>
>>> b
['p', 'y', 't', 'h', 'o', 'n']
>>> L = list()
>>> L
[]
متدهای کاربردی یک شی لیست¶
شی لیست تغییر پذیر است و متدهای آن برخلاف شی رشته یک شی جدید تغییر یافته را برنمیگردانند بلکه تغییرات را بر روی همان شی ایجاد میکنند.
(append(x- شیxرا به انتهای لیست مورد نظر اضافه میکند:>>> L = [1, 2, 3] >>> L.append(4) >>> L [1, 2, 3, 4] >>> L.append(['a', 'b']) >>> L [1, 2, 3, 4, ['a', 'b']]
عملکرد این متد
(L.append(xهمانند عمل[L + [xاست:>>> L = [1, 2, 3] >>> L + [4] [1, 2, 3, 4]
(extend(s- عضوهای شی دنبالهsرا به انتهای لیست مورد نظر اضافه میکند:>>> L = [1, 2, 3] >>> L.extend(['a', 'b']) >>> L [1, 2, 3, 'a', 'b']
>>> L = [1, 2, 3] >>> L.extend('py') >>> L [1, 2, 3, 'p', 'y']
(insert(i, x- یک عضو جدید مانندxرا در موقعیتی از لیست با اندیس دلخواه مانندiقرار میدهد:>>> L = [1, 2, 3] >>> L.insert(0, 'python') >>> L ['python', 1, 2, 3]
(remove(x- در لیست مورد نظر از سمت چپ به دنبال شیxمیگردد و نخستین مورد یافت شده را از لیست حذف میکند. چنانچه هیچ عضو برابری با شیxیافت نشود یک خطا گزارش میدهد:>>> L = [1, 2, 3, 5, 2 , 6 , 1] >>> L.remove(2) >>> L [1, 3, 5, 2, 6, 1] >>> L.remove(0) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: list.remove(x): x not in list
توجه
در مواردی که میخواهید اندیس خاصی از لیست را حذف نمایید؛ از دستور
delاستفاده کنید.([pop([i- عضو متناظر با اندیسiرا از لیست حذف و به عنوان خروجی برمیگرداند. چنانچه اندیس به متد فرستاده نشود به صورت پیشفرض آخرین عضو از لیست مورد نظر را حذف و برمیگرداند:>>> L = ['a', 'b', 'c', 'd'] >>> L.pop(2) 'c' >>> L ['a', 'b', 'd'] >>> L.pop() 'd' >>> L ['a', 'b']
توجه
نماد
[ ]در الگو متدها تنها روشی برای بیان اختیاری بودن عبارت درون آن میباشد و جزیی از متد نیست.([index(x[, n- در لیست مورد نظر از سمت چپ به دنبال شیxمیگردد و اندیس نخستین مورد یافت شده را برمیگرداند. این متد یک آرگومان اختیاری (n) نیز دارد که به کمک آن میتوان تعیین نمود اندیس چندمین مورد یافت شده برگردانده شود. چنانچه هیچ عضو برابری با شیxیافت نشود یک خطا گزارش میدهد:>>> L = ['s', 'b', 'c', 'a', 's', 'b'] >>> L.index('b') 1 >>> L.index('b', 2) 5 >>> L.index('z') Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: 'z' is not in list
(count(x- تعداد وقوع شیxرا در لیست مورد نظر برمیگرداند:>>> L = ['a', 'b', 'c', 'a', 'a', 'b'] >>> L.count('a') 3 >>> L.count(5) 0
()clear- تمام عضوهای لیست مورد نظر را حذف میکند. عملکرد این متد معادل دستور[:]del Lمیباشد:>>> L = [0, 1, 2, 3, 4, 5] >>> L.clear() >>> L []
>>> L = [0, 1, 2, 3, 4, 5] >>> del L[:] >>> L []
()reverse- عضوهای لیست مورد نظر را وارونه میکند:>>> L = ['a', 'b', 'c', 'd'] >>> L.reverse() >>> L ['d', 'c', 'b', 'a']
()sort- عضوهای یک لیست را مرتب میکند:>>> L = [4, 6, 2, 1, 5, 0, 3] >>> L.sort() >>> L [0, 1, 2, 3, 4, 5, 6]
>>> L = ['g', 'e', 'h', 'f', 'd'] >>> L.sort() >>> L ['d', 'e', 'f', 'g', 'h']
این متد در حالت پیشفرض به صورت صعودی اقدام به مرتب سازی میکند ولی میتوان با فرستادن مقدار
Trueبه آرگومان اختیاریreverse، شیوه آن را به نزولی تغییر داد:>>> L = [4, 6, 2, 1, 5, 0, 3] >>> L.sort(reverse=True) >>> L [6, 5, 4, 3, 2, 1, 0]
متد
()sortآرگومان اختیاری دیگری نیز با نامkeyدارد که میتوان با ارسال یک تابع تک آرگومانی به آن عمل دلخواهی را بر روی تک تک عضوهای لیست مورد نظر، پیش از مقایسه و مرتبسازی به انجام رساند. البته باید توجه داشت که تنها میبایست نام تابع به آرگومان متد فرستاده شود و نه الگو کامل آن؛ برای مثال تابع با الگو(func(xباید به صورتkey=funcفرستاده شود. چنانچه آرگومانkeyفرستاده شود، این متد عضوهای لیست را به تابع تعیین شده میفرستد و در انتها خروجی آنها را برای عمل مرتبسازی در نظر میگیرد. به نمونه کد پایین توجه نمایید:>>> L = ['a', 'D', 'c', 'B', 'e', 'f', 'G', 'h'] >>> L.sort() >>> L ['B', 'D', 'G', 'a', 'c', 'e', 'f', 'h']
همانطور که مشاهده میشود حروف بزرگ در ابتدای لیست مرتب شده قرار گرفتهاند؛ در واقع حروف بزرگ موجود در لیست به مقدار کوچکتری ارزیابی شدهاند که اگر به کد اَسکی این حروف توجه نمایید متوجه علت این ارزیابی خواهید شد. برای رفع این مشکل میتوان پیش از آنکه عمل مقایسه برای مرتبسازی انجام پذیرد با فراخونی تابعی بر روی عضوهای لیست، تمام حروف را به بزرگ یا کوچک تبدیل نماییم تا حروف در سطح یکسانی برای مقایسه قرار بگیرند:
>>> L = ['a', 'D', 'c', 'B', 'e', 'f', 'G', 'h'] >>> L.sort(key=str.lower) >>> L ['a', 'B', 'c', 'D', 'e', 'f', 'G', 'h']
در نمونه کد بالا
str.lowerبه چه معنی است؟در درس پیش با کلاس
()strکه از آن برای ایجاد شی رشته استفاده میشد آشنا شدیم و با برخی از متدهای آن که برای یک شی رشته در دسترس بود (مانند:()join) نیز کار کردیم. در آینده توسط درس مربوط به کلاسها خواهیم آموخت که میتوان با استفاده از نام کلاس و بدون ایجاد شی، متدهای داخل آن را فراخوانی نمود؛ در اینجا نیز همین اتفاق افتاده است و(lower(sمتدی تک آرگومانی داخل کلاسstrمیباشد که توسط نام این کلاس فراخوانی شده است.>>> str <class 'str'> >>> str.lower <method 'lower' of 'str' objects> >>> dir(str) ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
نکته
با استفاده از تابع آماده
()dir[اسناد پایتون] میتوانیم لیستی از تمام صفتها و متدهای در دسترس یک شی را دریافت نماییم.به جای متد
()sortمیتوان از تابع آماده()sorted[اسناد پایتون] نیز با همین توضیح استفاده کرد:>>> L = ['a', 'D', 'c', 'B', 'e', 'f', 'G', 'h'] >>> sorted(L) ['B', 'D', 'G', 'a', 'c', 'e', 'f', 'h'] >>> sorted(L, key=str.lower, reverse=True) ['h', 'G', 'f', 'e', 'D', 'c', 'B', 'a']
ایجاد پشته¶
«پشته» (Stack) ساختاری برای نگهداری موقت دادهها میباشد به شکلی که آخرین دادهای که در آن قرار میگیرد نخستین دادهای خواهد بود که خارج میگردد؛ این شیوه سازماندهی LIFO یا Last In, First Out خوانده میشود. پشته تنها از دو عمل (یا متد) پشتیبانی میکند: push که دادهای را بالای تمام دادههای موجود در آن قرار میدهد و pop که بالاترین داده را از آن خارج میکند.
ساختار پشته را میتوان به سادگی با استفاده از نوع لیست در پایتون پیادهسازی کرد؛ به این صورت که برای یک شی لیست متد ()append معادل عمل push و متد ()pop نیز معادل عمل pop خواهد بود:
>>> stack = []
>>> stack.append(1)
>>> stack.append(2)
>>> stack.append(3)
>>> stack
[1, 2, 3]
>>> stack.pop()
3
>>> stack.pop()
2
>>> stack
[1]
توپِل¶
نوع «توپِل» (Tuple) همانند نوع list است تنها با این تفاوت که تغییرپذیر نیست (بنابراین به نسبت مقدار حافظه کمتری مصرف میکند) و عضوهای آن درون پرانتز () قرار داده میشوند:
>>> t = (1, 2, 3)
>>> type(t)
<class 'tuple'>
>>> t
(1, 2, 3)
>>> print(t)
(1, 2, 3)
>>> import sys
>>> sys.getsizeof(t)
72
>>> t = () # An empty tuple
>>> t
()
در انتهای شی توپِل تک عضوی میبایست یک نماد کاما قرار داد؛ به مانند: (,1). از آنجا که از پرانتز در عبارتها نیز استفاده میشود؛ با این کار مفسر پایتون یک شی توپِل را از عبارت تشخیص می دهد:
>>> (4 + 1)
5
>>> a = (1)
>>> a
1
>>> type(a)
<class 'int'>
>>> t = (1,)
>>> t
(1,)
>>> type(t)
<class 'tuple'>
برای ایجاد شی توپِل حتی میتوان از گذاردن پرانتز صرف نظر کرد و تنها اشیا (یا عبارتها) را با کاما از یکدیگر جدا نمود:
>>> 5,
(5,)
>>> 1, 2 , 'a', 'b'
(1, 2, 'a', 'b')
>>> t = 'p', 'y'
>>> t
('p', 'y')
>>> 5 > 1, True == 0 , 7-2
(True, False, 5)
توجه
نوع توپِل به دلیل تغییر ناپذیر بودن، نسبت به نوع لیست در مصرف حافظه بهینهتر میباشد؛ بنابراین بهتر است در مواقعی که نیاز به تغییر خاصی در دادهها نیست از این نوع استفاده شود. همچنین در مواقعی که نباید دادهها تغییر کنند، استفاده از شی توپِل به جای لیست میتواند از آنها در برابر تغییر محافظت کند.
به دلیل شباهتهای بسیار شی توپِل به شی لیست از ارایه توضیحات تکراری اجتناب کرده و تنها به ذکر چند مثال در ارتباط با نوع توپِل میپردازیم:
>>> ('a', 'b', 'c') + (1 , 2, 3)
('a', 'b', 'c', 1, 2, 3)
>>> ('python', 0) * 3
('python', 0, 'python', 0, 'python', 0)
>>> t = ('p', 'y', [1, 2, 3], 5)
>>> 'p' in t
True
>>> 2 not in t
True
>>> [1, 2, 3] not in t
False
>>> (1, 'python') == (1, 'python')
True
>>> (1, 'python') == (1, 'PYTHON')
False
>>> t1 = (1, 2, 3)
>>> t2 = t1
>>> t2 == t1
True
>>> t2 is t1
True
>>> t1 = (1, 2, 3)
>>> t2 = (1, 2, 3)
>>> t2 == t1
True
>>> t2 is t1
False
>>> t = ('p', 'y', [1, 2, 3], 5)
>>> t[0]
'p'
>>> t[-1]
5
>>> t[:2]
('p', 'y')
>>> t[2]
[1, 2, 3]
>>> t[2][1]
2
>>> t[0] = 'j'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> t = ('p', 'y', [1, 2, 3], 5)
>>> len(t)
4
>>> len(t[2])
3
به دلیل ساختار ارجاعی بین اشیا در پایتون که توسط تصاویر بخش لیست نیز نمایش داده شد؛ اشیا تغییر پذیر درون شی توپِل، ویژگیهای خود را داشته و همچنان تغییر پذیر خواهند بود:
>>> t = ('p', 'y', [1, 2, 3], 5)
>>> t[2][1] = 8
>>> t
('p', 'y', [1, 8, 3], 5)
همچنین به نمونه کدهای پایین در مورد Unpacking توجه نمایید:
>>> a, *b = (1.1, 2.2, 3.3, 4.4)
>>> a
1.1
>>> b
[2.2, 3.3, 4.4]
>>> a, *b, c = (1.1, 2.2, 3.3, 4.4)
>>> a
1.1
>>> b
[2.2, 3.3]
>>> c
4.4
>>> a, *b = [1.1, 2.2, (3.3, 4.4)]
>>> a
1.1
>>> b
[2.2, (3.3, 4.4)]
>>> a, *b, c = [1.1, 2.2, (3.3, 4.4)]
>>> a
1.1
>>> b
[2.2]
>>> c
(3.3, 4.4)
>>> a, *b, c = (1.1, 2.2, (3.3, 4.4))
>>> a
1.1
>>> b
[2.2]
>>> c
(3.3, 4.4)
حتما متوجه شدهاید که عضوهای دنباله تنها با نوع لیست به نام نشانهگذاری شده انتساب داده میشود.
در هنگام انتساب متغیر توپِل به موضوع کپی نشدن اشیا تغییر پذیر توجه داشته باشید و در صورت نیاز از ماژول copy استفاده نمایید:
>>> t1 = ('p', 'y', [1, 2, 3], 5)
>>> t2 = t1 # No Copy
>>> t1[2][1] = 8
>>> t1
('p', 'y', [1, 8, 3], 5)
>>> t2
('p', 'y', [1, 8, 3], 5)
>>> t1 = ('p', 'y', [1, 2, 3], 5)
>>> import copy
>>> t2 = copy.deepcopy(t1) # Deep Copy
>>> t1[2][1] = 8
>>> t1
('p', 'y', [1, 8, 3], 5)
>>> t2
('p', 'y', [1, 2, 3], 5)
همانند شی لیست؛ شی توپِل نیز به دو متد ()index و ()count دسترسی دارد - این موضوع با استفاده از تابع ()dir قابل بررسی است:
>>> t = ('s', 'b', 'c', 'a', 's', 'b')
>>> dir(t)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'count', 'index']
>>> t.index('b')
1
>>> t.index('b', 2)
5
>>> t.index('z')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: tuple.index(x): x not in tuple
>>> t.count('a')
3
>>> t.count(5)
0
استفاده از راهنما را که فراموش نکردهاید؟!:
>>> t = ('s', 'b', 'c', 'a', 's', 'b')
>>> help(t.index)
Help on built-in function index:
index(...) method of builtins.tuple instance
T.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
(END)
هر زمان که نیاز به اِعمال تغییر در شی توپِل باشد؛ میتوان شی مورد نظر را به صورت موقت به یک شی لیست تبدیل کرد. در این حالت میتوان از ویژگی و متدهای شی لیست بهره برد و تغییرات دلخواه را اعمال کرد و در نهایت با یک تبدیل نوع دیگر دوباره به شی توپِل بازگشت. برای این منظور میتوان با استفاده از کلاس ()list یک دنباله - در اینجا یک شی توپِل - را به شی لیست تبدیل کرد و در طرف دیگر توسط کلاس ()tuple نیز یک دنباله - در اینجا یک شی لیست - را به شی توپِل تبدیل نمود:
>>> t = (1, 2, 3)
>>> type(t)
<class 'tuple'>
>>> L = list(t)
>>> type(L)
<class 'list'>
>>> L
[1, 2, 3]
>>> L.insert(0, 'python')
>>> L
['python', 1, 2, 3]
>>> t = tuple(L)
>>> t
('python', 1, 2, 3)
البته در مواقعی که میخواهید عضوهای درون یک شی توپِل را مرتب (Sort) کنید، نیازی به تبدیل نوع لیست نمیباشد و میتوانید از تابع ()sorted استفاده نمایید؛ این تابع مطابق آنچه که پیش از این معرفی شد یک شی توپِل را میگیرد و یک شی لیست با همان عضوها اما مرتب شده را برمیگرداند:
>>> t = ('a', 'D', 'c', 'B', 'e', 'f', 'G', 'h')
>>> sorted(t, key=str.lower, reverse=True)
['h', 'G', 'f', 'e', 'D', 'c', 'B', 'a']
کلاس ()tuple بدون آرگومان یک شی توپِل خالی را ایجاد میکند:
>>> t = tuple()
>>> t
()
>>> type(t)
<class 'tuple'>
😊 امیدوارم مفید بوده باشه
